Edge scale
Exponential growth of data
With the advent of the Internet, there has been exponential growth in data. Our ideas of data have changed dramatically. The last year the Encyclopaedia Britannica was printed was 2010. That final edition consisted of 32 volumes, weighed nearly 130 pounds, and contained approximately 50 million words or 300 million characters. It requires roughly one gigabyte (GB) of disk space to store the entire text of that final volume.
In 1989, a fast connection was 2,400 bits per second. It would take 38 days to download 1 GB. While writing this, my office internet tested at 240 Mbps or 10,000 times faster than 1989. It now takes less than a minute to download 1 GB.
The point of this history is that change has not stopped. Data is still growing exponentially. Exponential growth is a hard thing for the human mind to process. For instance, if you stacked one penny on top of another, and doubled the stack every day, in 38 days it would reach the moon.
From 1990 to 2020, the exponential growth of data was in the cloud. The cloud will continue to grow, but from 2020 onwards, that exponential growth will be at the edge.
The overlooked revolution in software
In 1981, my parents bought me my first computer, a TI 99/4A. It had 16 KB of RAM and a cassette tape player attached for storage. Bill Gates stated,
“I have to say that in 1981, making those decisions, I felt like I was providing enough freedom for 10 years. That is, a move from 64k to 640k felt like something that would last a great deal of time. Well, it didn’t – it took about only 6 years before people started to see that as a real problem.”
Before 2005, enterprise software applications were designed to run on a single computer. As your data grew, you needed a bigger computer. A single server needed more disk space, more RAM, more CPU cores. Servers got bigger and bigger to meet the needs of the largest use cases, such as large banking databases. However, most applications did not need all those resources. VMWare has made billions carving up those big servers into virtual servers (VMs) the size that most applications need.
With Internet growth, data eventually got so big that there was no computer big enough to handle the processing. In 2005, Doug Cutting and Mike Cafarella invented Hadoop, the beginning of what we call big data. Hadoop, and parallel processing in general, makes several individual servers look and act like one big computer. Hadoop took parallel processing out of the university and defense laboratories and into the corporate data center. From then on, all new software breakthroughs, such as Kubernetes and Kafka, were designed to run naturally on multiple servers. In fact, these new frameworks require a minimum of three servers to be fully functional. Parallel processing is everywhere.
In the meantime, however, hardware manufacturers are still making bigger and bigger boxes, as if nothing has changed in the software world. Each year, the processors grow: 64 cores, 72 core, 96 core CPUs. Fifteen years after the revolution in software and the hardware companies have still not changed course.
All of which leads us to a strange place. We take these giant servers and make them into a bunch of smaller servers using virtual machines. Then we lay a framework like Hadoop, Kubernetes or Kafka over all the virtual machines to make the look and act like a single bigger server. It all seems a bit mad.
What not just make small servers?
Thinking in edge scale
“Generals always fight the last war.”
It is human nature to take the solutions that worked for the last challenge and apply them without adaptation to the new challenge. We are seeing this with edge computing. Cloud was the last challenge. Engineers are applying the same solutions that work in the cloud to the edge without considering how very different edge is from cloud.
For instance, rack space is a primary consideration for a data center, so IT professionals place servers in the data center with very large core counts. Knee jerk reaction is more cores the better. When they plan their edge deployments, they attempt to use the same hardware that they use in the data center.
| Data center | Data center thinking at the edge | Edge thinking at the edge | |
|---|---|---|---|
| Number of locations | 1 | 2,000 | 2,000 |
| Number of servers per location | 100 | 1 | 3 |
| Total number of servers | 100 | 2,000 | 6,000 |
| Number of cores per server | 96 | 96 | 8 |
| Total cores | 9,600 | 192,000 | 48,000 |
| Price per server | $20,000 | $20,000 | $2,000 |
| Total price | $2,000,000 | $40,000,000 | $12,000,000 |
Table 2 Data center thinking vs edge thinking
If I have 100 servers in my data center with 96 core CPUs, that is 9,600 cores of compute power. That’s a lot of horsepower. (We will giggle about that in 20 years.) If a server cost 2 million for 100 servers.
Now suppose I have 2,000 stores and I try to deploy that same server. That is 192,000 cores of compute power. It is complete overkill. It would cost $40 million. Plus, it’s only one server per location. I have no high availability.
If, however, I deploy 3 servers of 8 cores each, that is 48,000 cores of compute. Note that it is five times more compute power than the data center. If each server is 12 million. As my compute needs at each store grows, I can incrementally add more 8 core servers.
Once you begin to think in terms of edge scale, you realize small servers are key.
Disruptive innovation
Edge computing is a disruptive innovation. Dr. Clayton Christensen introduced the concept of disruptive technology in a Harvard Business Review article in 1995. He fleshed out the concept in his books The Innovator’s Dilemma, The Innovator’s Solution and others, now considered mandatory reading in Silicon Valley.
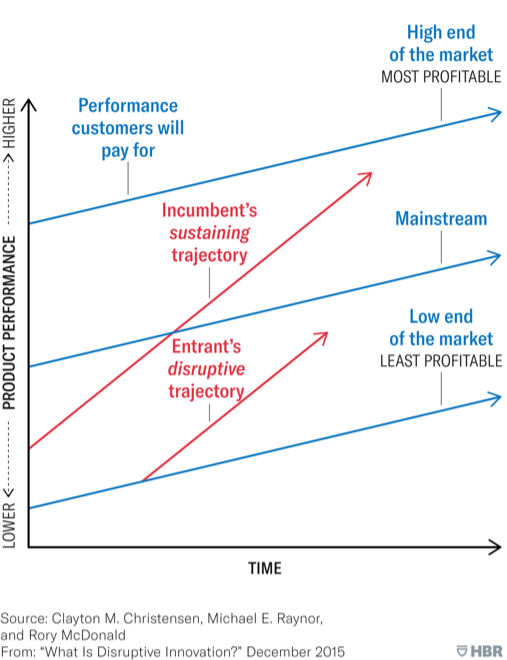
In short, Christensen asked, “Why have so many successful, well established technology companies been defeated by new companies in the same industry?” The answer is that there are two types of innovation: sustaining and disruptive. Sustaining technologies “give customers something more or better in the attributes they already value.”
“On the other hand, disruptive technologies introduce a very different package of attributes from the one mainstream customers historically value, and they often perform far worse along one or two dimensions that are particularly important to those customers.”
Established companies invest in sustaining technologies. They do not invest in disruptive technology for very logical reasons. It is not what their most valued customers want.
Successful edge computing technology has very different attributes than data center and cloud computing. In fact, those attributes are perceived as inferior. To hardware engineers, edge computers look like toys. “An eight core server? Who would ever want that?” they ask in disdain.
(It is not by coincidence that Dr. Christensen’s venture capital firm, Rose Park Advisors, is an investor in Hivecell. We are a textbook disruptive technology company.)
The tale of the air conditioning manufacturer
As we learned from Aesop as children, sometimes the best way to explain a concept is by allegory. Please indulge me.
Once upon a time there was an air conditioning manufacturer. The engineering team at the manufacturer had lots of engineers. They were all very smart.
A different mechanical engineer was responsible for the design of each of the components in the air conditioner. When an engineer needed a fastener, such as a bolt or screw, for his component, he would pick the best possible fastener for the job. It would have just the right tensile strength, length, diameter, thread count, etc. As a result, an air conditioner might have hundreds of different types of bolts and screws. And everyone was happy.
One day, a new head of engineering arrived. He looked at what the engineers had designed and made a declaration: “I want you all to redesign this air conditioner so that it has only one type of screw. If the screw is too strong for that connection, I don’t care. If the screw is too weak, then use two of them.”
As one might expect, there was much grumbling and discontent amongst the engineers. They knew their components better than anyone. They had worked hard to pick just the right screw for their particular part. Now this new guy was asking them to compromise their very smart design.
It took much cajoling and threats, and some old engineers even quit, but eventually the team did what the new head of engineering asked, and the results were amazing. Assembly line delays dropped. Field support costs dropped. Inventory costs dropped. Millions of dollars went right to the bottom line, that is, profit!
The supply chain is only as strong as its weakest length. If you run out of one novel screw for one subcomponent, your assembly line stops. If you are in the field repairing a unit and you do not have every type of novel screw, then you cannot complete your job.
By optimizing the components, the engineers were compromising the system as a whole. By compromising the subcomponents, the head of engineering optimized the system as a whole. The system is not just the machine. It is also the logistics, manufacturing and field support they create and maintain the machine.
The moral of our story is: The essence of good engineering is to compromise rather than to optimize.
The need for highly integrated solutions
Traditional solutions
Most edge vendors follow a pattern used before the cloud of separating the solution between hardware, software and system integrator. There are two challenges with this approach. First, each vendor is optimization his component of the solution while the solution as a whole is compromised. Second, the variability is unsustainable, at least at this point in the market maturity.
In the pattern mentioned, one company focuses on hardware. They don’t care what software you use, even operating system. They support everyone and everything. In the pattern, another company focuses on software. They will run on any hardware. They don’t pick favorites. The problem is, no vendor is focused on the solution. They are only focused on their piece of the solution. That means you, the customer, are stuck being the systems integrator, or you need to go hire one. If anything goes wrong, the finger pointing starts.
Unsustainable complexity
The finger pointing will eventually start because the system is unsustainable. There are too many variables. With edge deployments, system architects do with servers what the mechanical engineers in our previous story did with fasteners. They try to find the perfect server with just the right amount of disk space, CPU and RAM. The traditional hardware companies are more than willing to accommodate them. Each server model has an almost infinite number of CPU, memory and storage combinations. Like the engineer in our allegory, the edge architect has to say: “Use this one server configuration. If it is too big, I don’t care. If it’s too small, use two of them.”
Reducing the number of variables is key when deploying to hundreds or thousands of locations. Each hardware instance is something that must be tested, and not just once. You must test it for each update as well. For more details on how to calculate the cost of variability, see Appendix A of this handbook.
Disaggregation comes later
I caveat with “at this point in the market maturity.” We touched on disruptive technology earlier. Christensen observed that technologies cycle through periods of integration and disaggregation. When a technology is new, companies that have highly integrated products are generally more successful because they can eliminate variables and move to market faster. However, as the technology matures and the knowhow is disseminated, the more successful companies become disaggregated, sourcing out subcomponents to suppliers that can produce them more efficiently.
We see the same process in software. At the beginning, there are too many variables and unknowns, so a highly integrated solution will provide the most reliable performance. As the technology matures, the market can define clear, logical, effective boundaries, usually as protocols and application programming interfaces (API).
The trend of “fighting the last war” shows up here. Engineers see that the last technology has a dominant API or protocol standard. As soon as a new technology emerges, engineers rush to create the new protocol standard for the new technology. It is their path to stardom. Of course, everyone has the same idea, and we get several competing so-called standard protocols, few or none of which ever get adopted by industry. The fallacy is that the technology is too new. No one, not even these geniuses, knows what the actual needs of the market are yet. The disaggregation comes later.