Edge architecture
Technologies
In this section, we will review the key new technologies used for edge computing in manufacturing, namely containers, Kubernetes, Kafka and machine learning.
Containers
For personal computers, we install applications directly to the operating system (OS). We use the same approach for IPCs. We used to do the same for applications running on servers in the data center. However, to increase security and avoid resource contention, it was best to install one server application per server. The consequence of this approach was that huge amounts of compute resources went unused.
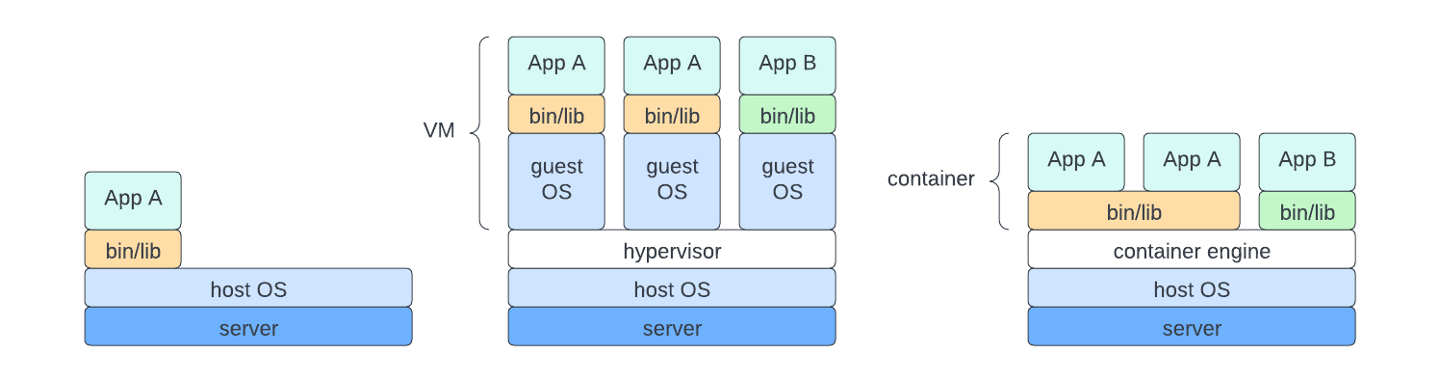
Virtual machines (VM) solved this problem of underutilized resources. A VM isolates an application in its own guest operating system, which removes the resource contention and security risks of having multiple applications running in the same OS. However, it created a lot of overhead in order run multiple instances of an OS on the same server.
Containers are the latest evolution in how to package and deploy applications. Containers are self-contained and isolated, so they address the issues of security and resource contention. However, they do not need a dedicated OS. Furthermore, containers can share common libraries. The result is dramatically increased efficiency in the use of compute resources. A server that might only be able to run 10 VMs can run hundreds of containers.
Kubernetes
Containers require orchestration. With dozens, perhaps even hundreds of containers running in a cluster, we need tools to monitor and manage them. Kubernetes is an open-source solution for orchestrating containers. It is not the only option, but it is the most commonly used.
Kubernetes provides the following for managing containers:
- Service discovery
- Load balancing
- Storage orchestration
- Automated rollouts and rollbacks
- Automatic bin packing
- Self-healing
- Secret and configuration management
Apache Kafka
Apache Kafka is an open-source distributed event streaming platform. It does not work the same way that traditional message oriented middleware (MOM) or messaging queues (MQ) work.
Kafka provides three key capabilities:
- To publish (write) and subscribe to (read) streams of events, including continuous import/export of your data from other systems.
- To store streams of events durably and reliably for as long as you want.
- To process streams of events either as they occur or retrospectively.
Kafka is distributed, highly scalable, elastic, fault-tolerant, and secure. Although originally designed for very large social media sites, it is particularly well suited for the needs of event sourcing at the edge.
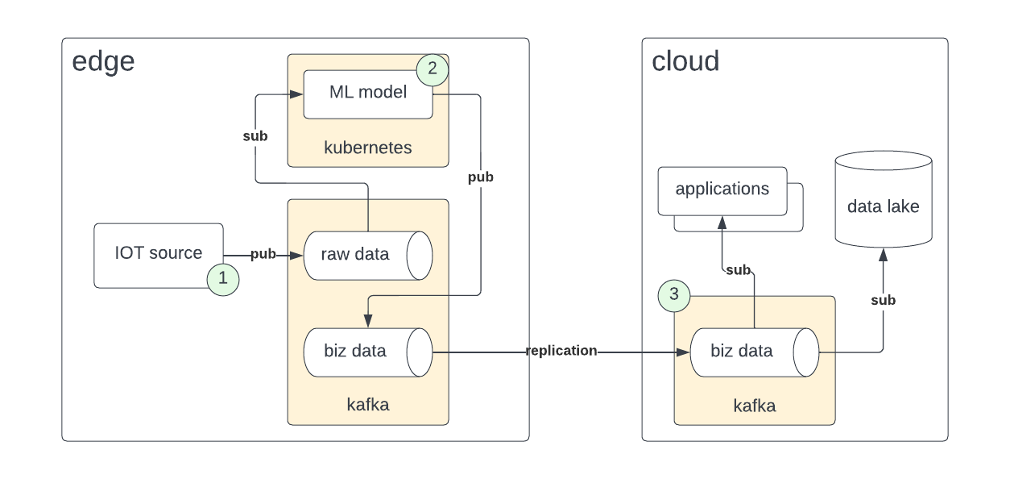
A basic pattern emerges in edge computing:
- Raw data from an IOT source is published to a Kafka topic.
- A machine learning (ML) model (or similar processing) subscribes to the raw data and publishes its results to an output topic.
- The output topic is replicated to the cloud or data center where the data can be sent to a data lake or other applications.
For instance, the raw data might be vibration data from a machine sampled at 1000 Hz. An ML model for predictive maintenance can detect normal or abnormal vibration. The output data is whether the machine is vibrating normally or abnormally. No one in the enterprise would make a business decision on the raw data. They are only interested in the output data. Pushing the raw data to the cloud would waste bandwidth and storage. It would also compromise autonomy and latency.
Realize that the connection between the edge and cloud can be intermittent. For example, a customer was processing data using this pattern in an oil field in West Texas. The connection to the cloud was by satellite. A piece of equipment blocked the line of sight with the satellite for six days. When the satellite communicate was reestablished, Kafka automatically replicated the data to the cloud, picking up exactly where it had left off. This would never happen using traditional messaging techniques. Someone would have to drive out to the oil well, download the missing data, drive in back to headquarters and write script to load the data into the systems.
Machine learning
When I studied robotics in the 1980s, Dr. Marvin Minsky of MIT was still casting a long shadow over the entire realm of artificial intelligence. The approached used then was to apply explicit logic in a sort of Aristotelian way to define the deductive processing of information. Programmers wrote logic (software) to apply to inputs to produce outputs. The approach didn’t work. The systems quickly became unsustainably complex without every achieving the ability to solve the most rudimentary problems.
Once Dr. Minsky was gone, a new approach opened, an organic approach. We humans do not learn language or anything fundamental by explicit logic. We learn through feedback loops. What if we let machines learned the same way?
Machine learning is the process of training a machine to create a model that produces the correct output for a given input. We do not concern ourselves with what is inside the model. We only care that given certain input the model produces certain output. We create the model through training. We give the model an input and then tell it what the correct output is. We repeat this process thousands or millions of times. All the while, the model is learning. Once the training is finished, we feed the model input it has not seen yet and see if it provides the correct answer. How often it provides the correct answer is called the model accuracy.
A great example of machine learning appears in the television sitcom Silicon Valley. In one episode, one of characters creates a model that can identify a hotdog. When he demonstrates the model to his colleagues, they are amazed and immediately assume it is capable of much more. They show it a pizza and it responds, “Not hotdog.” Their elation crashes.
The hotdog application in the TV show is completely realistic, and the response from the people is just as real. It is possible to create such a model with thousands of pictures of hotdogs and of things that are not hotdogs. What the model can do is remarkable, completely impossible in fact in the previous approach to artificial intelligence. A graduate student can train such an ML model in a matter of weeks. But the model can only do what it is trained to do, nothing more.
Hivecell architecture
Hivecell edge as a service platform provides compute on premise that looks and acts a lot like cloud. The Hivecell platform has all that you need to deploy solutions at the edge. It installs, runs and monitors your applications as containers or virtual machines.
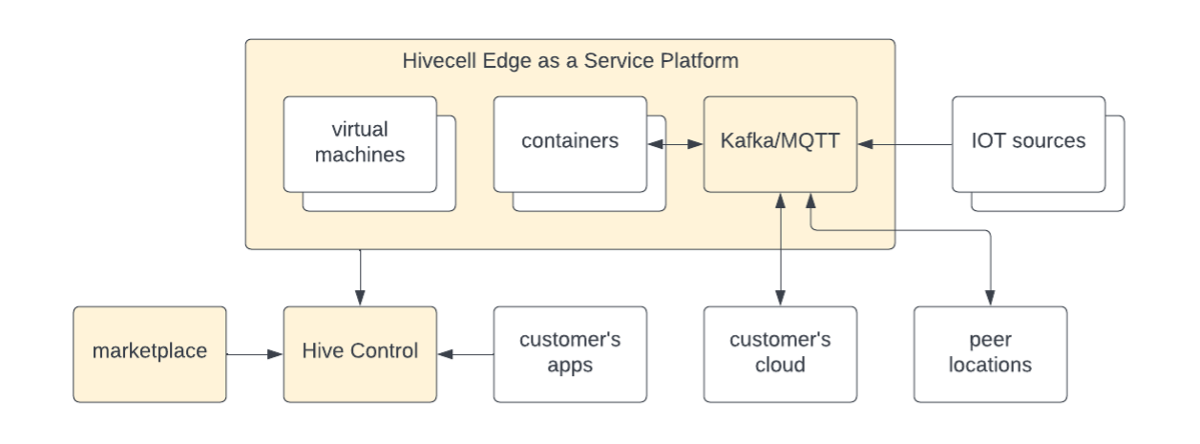
It also comes with Kafka for event sourcing. IOT sources connect to Kafka, usually through the MQTT protocol. Kafka also connects your edge data to the cloud and other edge locations.
Hive Control is the cloud-based monitoring and management console for all your Hivecell clusters, or hives. Hive Control comes with a marketplace of applications that are ready to deploy to hives. Customers connect their container and VM repositories to Hive Control and deploy applications in mass from there.
Fractal architecture
A fractal is a mathematical term for “infinitely complex patterns that are self-similar across different scales.” The most famous fractal is Mandelbrot, shown below.

With the advent of edge computing, we are seeing a fractal computer architecture arise. The same architecture is used at different layers at different scale. The architecture has two primary components: containerization and event sourcing.
Containerization starts with breaking an application into multiple independent components, called microservices, but it goes further by making these components idempotently deployable, which is containers. A container orchestrator such as Kubernetes handles complex interdependencies of the containers. It also enables high availability and scale up, that is, the ability to have multiple instances of a container running simultaneously.
Event sourcing is fundamental to scalable distributed systems. The fundamental idea is that every change in state is recorded as an event. Applications can independently recreate the state, also known as a materialized view, by reading and applying the sequence of state changes. Kafka is designed to be the backbone of an event sourcing architecture.
The web applications that you use daily such as Google and LinkedIn were the first to adopt the new architecture because they were the first to deal with the challenges. Google built Kubernetes and LinkedIn built Kafka internally out of necessity and released them to the community as open source. Enterprise applications are nowhere near the scale of Google or LinkedIn. Nevertheless, the architecture pattern has proven itself very useful for enterprise application development. As companies push their applications to regional data centers (near edge), they are deploying the same infrastructure, but at a smaller scale.
Hivecell provides the same architecture at an even smaller scale, small enough to deploy on the factory floor. We are even seeing smart devices adopt the pattern, having containers and message bus running inside the device. With the explosion of new novel chip startups, we will see the architecture manifested in the silicon itself.