Introduction to Uniform Resource Names
From 2002
Uniform resource names (URN) are a fundamental technology of the Internet that has gone unused. The purpose of this document is to provide a basic introduction to uniform resource names (URN) for executives who must make technology decisions. This document reviews what URNs are, the challenges to making them work and the benefits to using them. In the process of our discussion, we will review uniform resource locators (URL) and the domain name service (DNS). Finally, we will discuss the business decision for why an organization might implement a new URN namespace. This document assumes that the reader has used the Internet.
Introduction
Uniform resource locator
Most of us are familiar with uniform resource locators (URL). Resource is just a technical term for anything that is accessible on the Internet. Text files, HTML pages, images, video streams and applications are all resources. A uniform resource locator is a standard means of locating a particular resource. The URL is sometimes called the web page address. It is what you type in your browser to jump to a particular page. For instance, the URL of this document is
https://jeffreyricker.com/docs/urns.
A URL specifies the location of a specific resource on a specific server on the Internet. For instance, the URL of this document specifies that the web server’s domain name is jeffreyricker.com, the path on the server is /docs/urn. This breakout is shown in Figure 1.
| protocol | domain name | path |
|---|---|---|
| https:// | jeffreyricker.com | /docs/urns |
Figure 1 The elements of a typical URL
URLs are designed to work the way the Internet works. The Internet employs several protocols and it locates specific computers using domain names. An HTTP server provides access to files from particular directories or file paths. Thus, you can see the example in Figure 1 fulfills these functional requirements.
Uniform resource names
Uniform resource names (URN) allow us to reference Internet resources not by their network location but rather by their unique name. A URN consists of the prefix urn, a namespace and a unique name. That’s it. It contains no information about the location of the resource.
| prefix | namespace | name |
|---|---|---|
| urn: | isbn: | 1-56592-512-2 |
Figure 2 The elements of a URN
Figure 2 provides a sample URN. It begins with the prefix urn. The namespace is isbn, which is the International Standard Book Numbering system. Every book published in the United States has a ten-digit ISBN number. The ISBN namespace allows us to use the ISBN number of a book as a URN to reference Internet resources regarding that book.
URNs have several advantages over URLs. By separating reference from physical location, URNs can have a persistence that URLs cannot match. More importantly, however, URNs allow us to access information the way that is most convenient to us in our business processes, rather than the way that is most convenient to the Internet.
URNs have one significant disadvantage. They contain no information about the location of the resource, which begs the question how does one use a URN to find a resource on the Internet? Answering this question is the fundamental challenge to implementing URNs.
In this paper we will discuss the advantages to using URNs. Before we can discuss the technology challenges to implementing URNs, we will review the Internet infrastructure that makes URLs and URNs work. Finally, we will discuss the business decision for why an organization might implement a new URN namespace.
Advantages of URNs
Align access with business practices
URNs allow us to access Internet resources by a unique name rather than by their physical location. That means URNs allow us to access information the way that is most convenient to us in our business processes, rather than the way that is most convenient to the Internet.
Organizations have been managing and sharing vast amounts of information long before the Internet. Many professional organizations have created unique identification systems for referencing data. These organizations and their members have spent years perfecting and employing these numbering systems. We use them to manage and execute our business processes. For instance, we use D-U-N-S numbers as identifiers for our trading partners and we use UPC barcodes as identifiers for our inventory.
The Internet provides an excellent means for publishing and accessing information. The preponderance of information now available on the Internet is overwhelming. In 2002, Google claims to search more than 2 billion web pages. That means there are trillions of bytes (terabytes) of data currently on the Internet and growing.
The Internet has made publishing data trivial and finding that data terribly difficult. Entire companies such as Yahoo and Google exist to help us locate information on the Internet. The challenge stems in part from the way we access information on the Internet. URLs force us to find information based on its network location, which may or may not have a logical association with the information itself.
Suppose that you had a handheld wireless web browser, such as a Palm Pilot, and you wanted to look up more information on a product you found on the shelf. The label of the product has the brand name and a UPC barcode. To find information, you would first have to guess at what the company’s domain name is. It may be the brand name itself, but then again, it might not. Once you do find the domain name, you then have to search through the website to see if does actually provide information on the product.
If there was a URN namespace for UPC barcodes, then you could simply type in the barcode and be taken directly to the information on the product. The URN as a reference is more aligned with the realities of business. We have barcodes on our product packages, not network locations. By using URNs, we enable organizations to share and access their data in the way they are accustomed to. We alleviate burdens from users and developers alike.
Drilldown data reference
A URN is a unique identifier that is traversable like any URL as a link to information published on the Internet. URNs can serve as an unambiguous reference within databases and documents. They can identify the information and provide drill-down to further information all at the same time.
For instance, an electronic purchase order could use a URN as a product identifier for a particular line item as shown in Figure 3. Since the item description is a URN, it automatically serves as a hyperlink to further detailed information. Conceivably, you could click on it and be taken directly to the product details on the Internet.
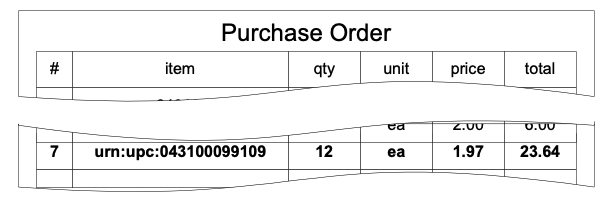
Figure 3 Purchase order with URN
The URN can also serve the same role as a relation in a relational database. Using URNs as identifiers within a database, there is no need to replicate information in the database published elsewhere in order to have it related. URLs could never effectively serve this purpose because they are unwieldy in length, have no logic structure as a data reference and, most importantly, they lack persistence. If a resource moves to another network location, then the URL is broken. The effort in making sure the URL links are fresh and not broken defeats the purpose of using them as a database relation. Using a URN, the resource can move anywhere and the reference will still work.
Power unused
The URN can also serve the same role as a relation in a relational database. Using URNs as identifiers within a database, there is no need to replicate information in the database published elsewhere in order to have it related. URLs could never effectively serve this purpose because they are unwieldy in length, have no logic structure as a data reference and, most importantly, they lack persistence. If a resource moves to another network location, then the URL is broken. The effort in making sure the URL links are fresh and not broken defeats the purpose of using them as a database relation. Using a URN, the resource can move anywhere and the reference will still work.
Domain name service
IP addresses
The Internet is a network of networks. It is an inter network, as in inter state or inter national. The Internet is a kind of least common denominator among networks. As such, it has to be kept really simple. Every computer connected to the Internet has assigned to it a unique number called an Internetworking Protocol (IP) address. This address is comprised of four numbers separated by a period, each with a value between zero and 255. For instance, 192.168.0.101 is a valid IP address.
Remembering the IP address of a particular computer is difficult for many people. Very quickly, people began to assign name aliases to certain IP addresses. For instance, without aliases one would have to type
open 192.168.0.101
Instead of having to remember 192.168.0.101 all the time, one could assign that value to a name. Suppose we decide to name the computer dingo. That’s a lot easier to remember than four numbers. One could assign the IP address to the name dingo as follows
dingo = 192.168.0.101
open dingo
This became such a common task that a standard file was created named host.txt to store all these aliases.
dingo 192.168.0.101
vulture 192.168.0.103
sahara 192.168.0.1
camel 192.168.0.102
In ancient times, when there were only a couple of hundred computers connected to the Internet, every computer kept a copy of the host table for the entire Internet. Someone at the Stanford Research Institute maintained a master table. Others would periodically download a copy of the master to their machine. Changes and updates were e-mailed to Stanford. Obviously this process could never work for more than a couple of hundred computers.
In September 1984, the Internet replaced this centralized, manual process with the Domain Name Service (DNS). It has been used ever since. It is what has enabled the Internet to grow beyond a couple of hundred computers to the millions that are connected today. There would literally be no “dot-com” boom, or dot-com bust for that matter, without the DNS. That’s because DNS establishes the .com domain.
DNS hierarchy
Under the DNS system, every computer joins the Internet under a domain hierarchy. At the top of the hierarchy is a limited set of top-level domains. There is .edu for education, .mil for the US military, .org for non-profits and .com for the commercial sector. There are also two-letter top-level domains for every country, such as .uk for the United Kingdom and .de for Germany (Deutschland).
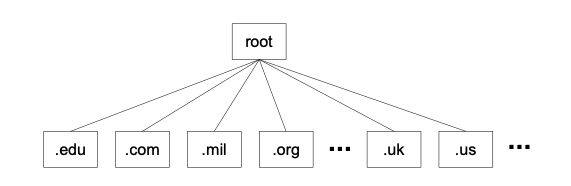
Figure 4 Top level domains in the DNS hierarchy
Each domain has the delegated authority to create its own sub-domains. The .mil domain has created the sub-domains army.mil, navy.mil, etc. The .com domain has created millions of sub-domains. Trans-enterprise owns one of these sub-domains, xeic.com. Trans-enterprise, in turn, has created its own sub-sub-domains for each field office. We have nyc.xeic.com in New York City, lisle.xeic.com in Lisle, Illinois, and dc.xeic.com for Washington, DC. This hierarchy is shown in Figure 5.
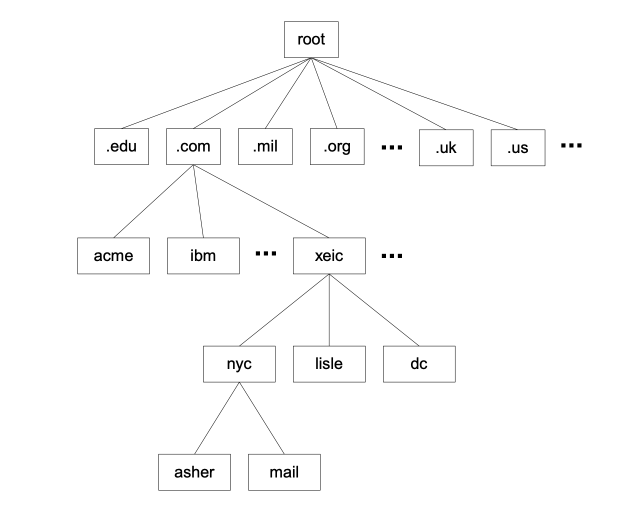
Figure 5 Sub-domains in the DNS system
Within the DNS system, every computer joins the Internet from within a domain. In Trans-enterprise’s New York office, the computers join the Internet in the nyc.xeic.com domain. So the mail server there has the IP address 192.168.100.5 and is named mail.nyc.xeic.com. Another machine with IP address 192.186.100.12 is named asher.nyc.xeic.com.
Most web servers are named www. If our web server were in our New York office, then it would be named www.nyc.xeic.com. Most small companies have only one computer accessible to the Internet, their web server, so the extent of their domain hierarchy is simply www, as in www.xeic.com..
Every organization like Trans-enterprise that manages a domain keeps its own DNS table. When the organization adds a new computer to their network, they enter the name into their local DNS table. So, in our example, there is a DNS table maintained in the New York office. The entry for the computer named asher was placed in that DNS table.
Each DNS table has a record that points to the DNS table of the next higher domain. The DNS table at nyc.xeic.com points to the DNS table at xeic.com which in turn points to the DNS table for .com.. At scheduled intervals, perhaps once a day, the lower domains and the higher domains synchronize. The DNS at nyc.xeic.com informs the DNS at xeic.com of any changes, and vice versa. Likewise, the xeic.com domain informs the .com top-level domain of any changes, and vice versa. Finally, .com updates the root domain. In that way, changes made at the far end of the Internet are propagated throughout the Internet.
DNS resolution
In order to connect as many networks as possible, the Internet is kept very simple. Applications can only find other computers using the IP address. Nevertheless, most applications such as e-mail and web browsers employ domain names. For every Internet request, the domain name must be translated into the actual IP address. For instance, a request to mail.nyc.xeic.com must be translated into the address 192.168.100.5. If the name cannot be translated into the number, then the request will never go through. This translation of domain names into IP addresses is handled through what is called a DNS resolution.
There is an adage in engineering that states, “Half of knowing something is knowing where to find it.” Due to the hierarchy of the DNS system, any computer can ask its local DNS to resolve any DNS name because, although it may not have the answer stored in its own table, it knows where to find it. Suppose that a computer in Timbuktu wanted to contact the computer mail.nyc.xeic.com.. That computer would ask its local DNS to resolve the DNS name to an IP address. The local DNS does not know the IP address of mail.nyc.xeic.com, but it does know how to find it.
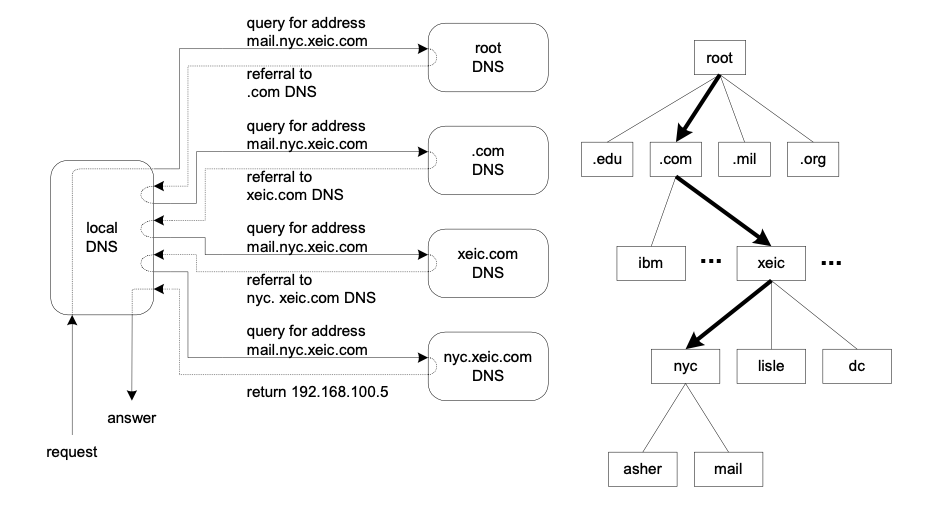
Figure 6 DNS resolution
Figure 6 shows how the local DNS in Timbuktu would go about finding the IP address for the Trans-enterprise mail server.
- The local DNS would first ask the root DNS server for the IP address. The root server would refer the local DNS to the DNS of the .com domain.
- The local DNS would then ask the .com DNS. The .com DNS would refer the local DNS to the xeic.com DNS.
- The local DNS would then ask the xeic.com DNS, which would refer it to the nyc.xeic.com DNS.
- The local DNS would then ask the nyc.xeic.com for the IP address. This time, the local DNS gets the actual IP address 192.168.100.5.
- The local DNS returns the IP address to the computer in Timbuktu. Now that computer can connect to the mail server in New York
Real DNS
The DNS resolution enables any computer to find the IP address of any other named computer. Going by the previous example, one might think that this is a lot of work for every single request over the Internet. Although this example is an accurate explanation of how the basic DNS system works, the system has some features to make it more efficient. For instance, there are mechanism in place such that not every single request need go directly to the root DNS.
More features, however mean more complexity. Actual DNS tables can be very large and cryptic. There is no easy way to debug DNS tables. If one of the records is wrong or has a typo, that bug can populate out across the Internet over night. The result of a bad DNS record can leave your computers inaccessible by their DNS names. In e-commerce, such an outage could be costly. As such, one of the primary duties of a network administrator is to maintain the DNS.
Making URNs work
Barcode example
Suppose there was a URN namespace for barcodes. What would be the advantage of having it? How would it work?
The immediate advantage would be rapid access to product related information using the barcode number itself. Under the current situation, a company can certainly publish product information on its website, but there is no means for you to access that information using only the barcode. The barcode does not tell you the product manufacturer’s name, domain name or where on the website the product information is located.

Figure 7 Sample UPC barcode
An organization could create a website that linked all barcodes to their specific web pages, that is, their URL. Such a website might take a URL such as
http://www.barcodelookup.com/lookup?upc=043100099109
The URL forms a query, with the last 10 digits being the barcode numbers. The URL could return a forwarding URL, redirecting the browser to the appropriate web page.
There are several problems with this approach.
- The lookup website becomes a bottleneck. Every single barcode request must hit the same site. The site will require more and more equipment and network bandwidth as the usage of the site grows. That equipment will cost money, which means the service of the site cannot remain free.
- The lookup website creates an organization standing between a product manufacturer and its brand. This interposing might be interpreted as a threat to brand control.
- Multiple organizations might create barcode lookup sites. The user is then faced with the challenge of knowing which website to use for lookup. Each site may be only partially complete.
- The user is faced with recursive lookup. The first URL directs to another URL. What if the second URL redirects to a third URL? A human can easily figure this out, but an application looking up the information must be programmed to handle such a contingency.
Each company will store product information a different way. Some will have static HTML pages. Others will have applications for dynamically generating product information from a relational database. These applications will have complex, cryptic and sometimes lengthy URLs that may actually change with each session.
The central server is faced with a choice: either (1) the server keeps a record of every specific UPC mapped to its resource or (2) the server delegates the specifics to the manufacturer. The first option of centralization is simply unmanageable. The founders of the Internet discovered as much before they created the DNS system. Organizations such as UCC and ISBN that manage unique numbering systems usually delegate number assignment. For instance, the UCC assigns the first few digits to a manufacturer and that manufacturer assigns the remaining digits to its products.
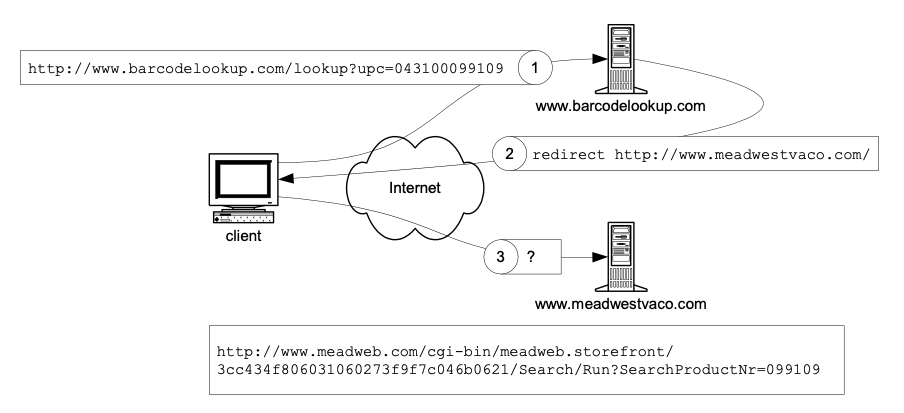
Figure 8 Challenge of using URL-based lookup of a UPC barcode
Delegation of a lookup is quite unpractical using URL. Figure 8 shows the challenges of using a URL-based delegated lookup for our UPC barcode example. The client knows to form a URL as query to the barcodelookup.com website. That site knows that 043100 is the prefix assigned to the Mead Corporation, so it redirects the client to the corporate website http://www.meadwestvaco.com/. However, the lookup at Mead is actually
http://www.meadweb.com/cgi-bin/meadweb.storefront/
3cc434f806031060273f9f7c046b0621/Search/Run?SearchProductNr=099109
How could the client possibly anticipate such a query?
URN infrastructure
Before 2002, URNs did not work. URNs were a published standard of the Internet. You could use a URN as an identifier, but you could not use a URN to actually link to a resource. Since the URN does not contain any location information, there was no way to locate the resource on the Internet.
The IETF has now published the means to make URNs work. The means calls for using the DNS as Dynamic Delegation Discovery System (DDDS). It is very simple and very clever. The DDDS works by mapping some unique string to data stored in a DDDS database by iteratively applying string transformation rules. The algorithm is shown in Figure 9.
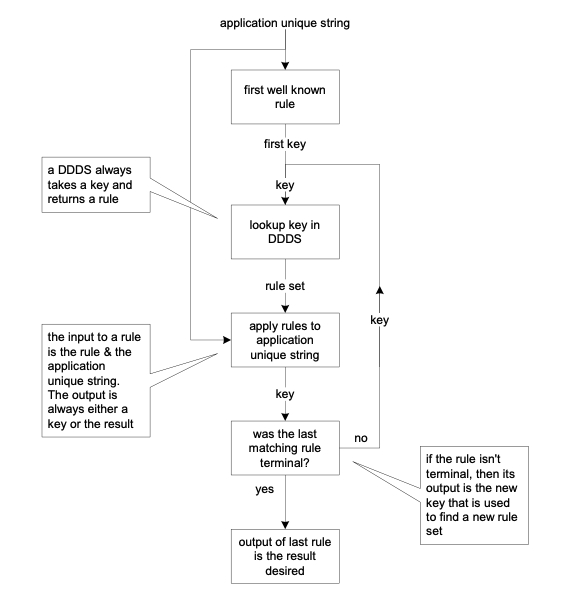
Figure 9 The DDDS algorithm
To apply this algorithm for our purpose, the unique string is the URN, the DDDS database is the DNS tables, the rules are regular expressions and the desired result is a network location. The whole thing works only when the IETF turns on the first well known rule at the root DNS.
Regular expressions are a common tool used in the Unix/Linux community. They are used in programming languages such as Perl, Python, Tcl and Awk. Regular expressions are usually employed to transform strings. For instance, the following regular expression strips a string of leading and trailing space characters
s/^\s*(.*\S)?\s*$/$1/
Regular expressions are exceedingly compact and powerful, which make then well suited for the DDDS rule set. However, they can also be exceedingly cryptic, which increases the complexity of implementing URNs.
Hurst’s Law on the Conservation of Complexity states that complexity of a system cannot be eliminated; it can only be displaced. URNs make accessing information on the Internet much easier because they allow us to reference information in the way that is convenient to our current business processes. Since the complexity of the Internet cannot be eliminated, if the access to information became simpler, then to where did the complexity get displaced? The answer is the DNS.
We discussed earlier that DNS tables can be complicated things that are difficult to debug. To make URNs work, we are now adding regular expressions, which can also be complicated and difficult to debug. Thus, URNs make the DNS exponentially more complex, a challenge that demands new software.
Creating a URN namespace
Process
To create a .com domain such as trans-enterprise.com, you simply file a form with Verisign or some other registering agent and pay $75. To create a URN namespace is a bit more complicated. The IETF does not wish to see an explosion of URN namespaces like it saw with dot-com domains. Namespaces are treated almost like top-level domains.
To create a URN namespace, you must submit a formal proposal to the IETF for review. If approved, then the namespace is registered with the Internet Assigned Numbers Authority (IANA). There are some criteria for approval. For instance, a formal namespace must:
- Provide benefit to some subset of users of the Internet
- Be globally functional and not be limited to small communities or networks not connected to the Internet
Also, the organization maintaining the namespace should:
- Demonstrate stability and ability to maintain the namespace for a long time
- Demonstrate ability and competency at name assignment to avoid name conflicts
- Commit to not re-assign existing names and allow old names to continue to be valid
So far, the IETF has approved only a handful of namespaces.
Benefits
Organizations that provide unique identifiers to its members should consider establishing a URN namespace. URNs allow these organizations to unleash the power of their well-established, unique identifying systems across the Internet.
For the organization members, URNs make many types of e-commerce efforts far easier to implement and deploy. These organization members have already adopted the unique numbering systems within their business processes. By making the numbering system a URN namespace, members can more readily employ their existing business processes over the Internet.
For the organizations themselves, URNs enable them to provide value-added electronic commerce service to their members. That means either greater member retention or increased revenues, or both. The IETF has anticipated that a formal namespace may make use of a fee-based, privately managed, or proprietary registry for the assignment of URNs within the namespace. Thus, organizations that maintain unique numbering systems can charge their members for making particular sets of numbers available as URNs.
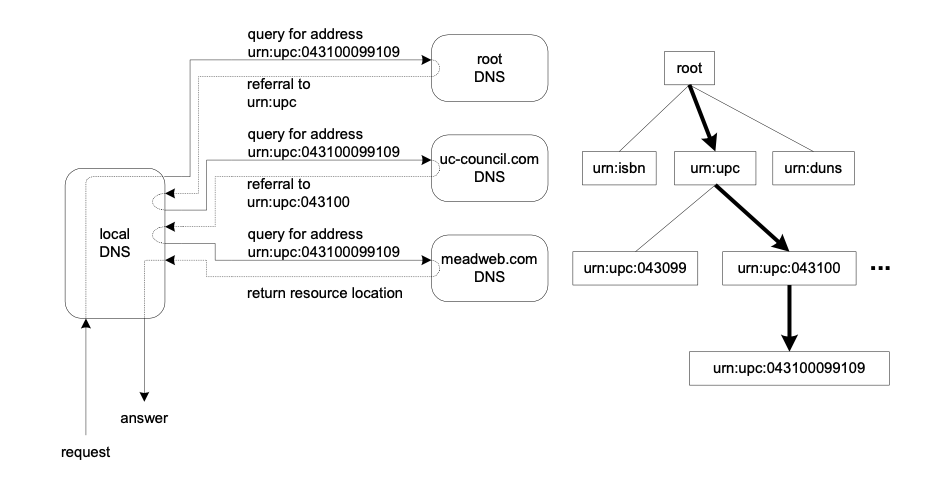
Figure 10 URN resolution
Just as the IANA must “turn on” the namespace at the root DNS, the organization must “turn on” particular sets of numbers as valid URNs. Continuing with our earlier barcode example, Figure 10 shows the delegation of a URN namespace. The root DNS points to the UCC as the UPC namespace manager. The UCC in turn points to the Mead Corporation as the manager for all UPCs that begin with 043100. The Mead DNS can then manage the assignment of urn:upc:043100099109 to a particular resource. No UPC URN will forward to Mead without the UCC’s approval. Likewise, no UPC URN starting with 043100 will forward to a resource without Mead’s approval. Thus delegation and ownership are achieved.
Next steps
Organizations that provide unique numbering systems should begin investigating immediately the potential benefits of creating a URN namespace.
Creating the URN namespace will require lead-time and proper preparation to gain IETF approval. Organizations should plan their licensing revenue models and marketing alliance strategies.
The infrastructure must be in place. The organization must have an effective and well documented process for assigning and maintaining URNs. Most of that process will already exist with the organization’s unique numbering system. However, some network issues must be accounted for. Furthermore, the organization must have the DNS infrastructure to support the effort. If it does not, then it should find a partner who does.
Finally, the organization should form a rollout strategy. Launching a new service requires planning and effective communication. Members will need to learn what advantages the URN namespace provides and how to employ it. Organizations that are not accustomed to providing technical support will need to find a partner who is.
URNs are a fundamental capability of the Internet that has gone untapped. URNs have the potential for making e-commerce much easier to deploy and use. Now that potential can be unleashed. It is up to people like you to unleash it.
References
Original references
- Paul Albitz and Cricket Liu. DNS and BIND. (O’Reilly: 1998).
- Jeffrey E. F. Friedl. Mastering Regular Expressions. (O’Reilly: 1998).
- Michael Mealling. “Dynamic Delegation Discovery System (DDDS) Part One: The Comprehensive DDDS Standard” (IETF: 2002)
- Michael Mealling. “Dynamic Delegation Discovery System (DDDS) Part Two: The Algorithm” (IETF: 2002)
- Michael Mealling. “Dynamic Delegation Discovery System (DDDS) Part Three: The DNS Database” (IETF: 2002)
- Michael Mealling. “Dynamic Delegation Discovery System (DDDS) Part Four: The URI Resolution Application” (IETF: 2002)
Updated references
Dynamic Delegation Discovery System (DDDS)